È un periodo in cui sto popolando la mia categoria Articoli che piacciono ad Aranzulla. Oggi è il turno di una guida la cui trama è tratta da una storia vera.
Preambolo: è quasi certo che il tuo stupido blog non sia ad alto traffico. In questo caso trarrai benefici da questa lettura.
Visualizziamo il caso dell’edizione in lingua italiana di Wikipedia. Genera un traffico di duecentosettantamila visite all’ora. Anzi, prendiamo anche quella in lingua inglese. Vanta circa quattro milioni di visite all’ora. Non so se mi spiego. Quattro milioni. Ma non basta. Prendiamo pure tutte le duecentonovantasei dannatissime edizioni linguistiche di Wikipedia, insieme a tutte le diciotto edizioni linguistiche di Wikiversity, e non fatemi contare le edizioni linguistiche di Wikivoyage, Wikibooks, Wiktionary, Wikiquote, Wikisource, senza dimenticare Wikimedia Commons e Wikidata.
Non so se riusciamo ad immaginare sedici miliardi di accessi al giorno.
Ora immaginate che siate voi i possessori di un sito di (relativamente) insignificativa visibilità (con tutto il rispetto, ma di fronte allo scenario che stiamo immaginando siamo tutti dei peti al vento). Anche se magari avete davvero la bellezza di venti visite l’ora (di cui solo 2 di nostra madre!). Immaginiamo poi che domani il vostro sito sia promosso con un banner bello GROSSO in cima ad OGNUNO di quei siti enumerati precedentemente, esponendovi potenzialmente alla pioggia di centinaia di migliaia di accessi simultanei.
Che fare?
Per non saper nè leggere nè scrivere ci siamo preparati un attimo.
Sì, perchè il sito in questione è Wiki Loves Earth; i proprietari del dominio sono una piccola e tenera associazione culturale di miei amichetti (Informazioni.Wiki). Il motore del sito è WordPress. Il server è il mio. E sì, la Wikimedia Foundation ha ficcato un bannerone su ogni suo sito, come ad ordinare alla gente di prendere a calci nel culo tale sito.

Contrariamente ad ogni mia aspettativa siamo riusciti a gestire la situazione. Alla grande. Direi che è stata una passeggiata. Unica ragione: la gente non clicca sui banner nei siti. I numeri sono stati inferiori alle aspettative con appena 11-15 mila accessi al giorno. Circa 500 visite spalmate ogni ora. Il che non è tantissimo ma non è nemmeno poco per il server di un ragazzetto.
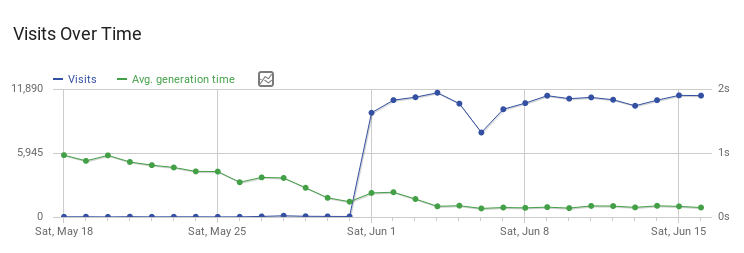
Questo grafico è tratto dalla nostra istanza Matomo (perchè nel 2019 siamo sufficientemente evoluti per fare statistiche senza—licenza poetica—inculare la privacy dei visitatori con Google Anal-ytics o altri incubi di cui potrei parlare per ore).
Possiamo notare la linea blu che rappresenta la pace prima della tempesta, nella prima parte del grafico, con circa un centinaio di accessi al giorno. Ad un certo punto, BOOM, 11.000 accessi al giorno. Ora guardiamo la linea verde. È il generation time. In teoria, più hai visite, più metti sotto sforzo la macchina, più il generation time aumenta. Noi lo abbiamo fatto calare facendo tuning ogni giorno. Fico, vero? È sempre sceso, arrivando ad abbattersi da circa 6 secondi ad un molto più gestibile 0.2 secondi.
Da questa storia ho imparato che:
- È sufficiente partire da questa guida definitiva per velocizzare WordPress!1!
- Ridurre al minimo le risorse in ogni pagina a qualsiasi costo ripaga moltissimo
- Adotta cache lato webserver con mod_cache o Varnish o chi per esso
- Elimina qualsiasi strato di cache lato applicativo (vari plugin WordPress “iper-super-mega-cache-sarcazzo”) dato che questi ultimi sono scritti coi piedi, garantito, come ben spiegato nella guida definitiva per velocizzare WordPress!1!
- Se usate Apache, ovviamente disabilitate AllowOverride e tutte le altre merde inutili di cui manco ti sei documentato.
- Fai tuning di qualsiasi cosa con Apache Benchmark o amici simili. A/B. Prima dopo. Flip flop. Fallo e sarai ripagato.
- A quanto pare la gente non clicca sui banner. Quindi se ti linkano da ogni progetto della Wikimedia Foundation non è da vedersi come terrorismo. Keep calm and stop tearing off cables.
Qualche dritta su mod_cache
Come funziona mod_cache? Esso arnese è uno strato in cui salvare su disco le risposte dell’applicativo (WordPress) e riconsegnarle ad altri visitatori che chiedono le stesse pagine già richieste. Questo abbatte drasticamente i tempi di generazione della pagina, perché è già stata generata. È lì. Non devi cucinare la ricetta per tutti al volo, non devi manco scongelarla, è già lì sullo scaffale e gliela devi solo lanciare al cliente. I parametri di default vanno bene per la maggior parte dei casi. Non vengono messi in cache i file troppo piccoli, i file troppo grossi, i file richiesti via POST, etc. Addirittura la vostra distribuzione GNU/Linux se non fa schifo abiliterà da sola il demone apache-htcacheclean che pulirà la cache vecchia (o almeno così avviene in Debian GNU/Linux).
Infatti, mod_cache è una pezza di software abbastanza rispettabile che fa il suo sporco dovere, e bene, se l’applicativo soddisfa una serie di banalità, tipo spedire correttamente header HTTP Expires, preferire richieste stateless evitando le sessioni, usare GET solo per richieste idempotenti, etc.
Chiaramente la maggior parte dei CMS fa soltanto una di queste cose, se non nessuna.
Dovrete girare intorno a tutte le lacune dell’applicativo ed istruire voi mod_cache. Ad esempio, mod_expires viene eseguito prima di mod_cache quindi potete usarlo per sopperrire alla mancanza di Expires dell’applicativo. Potete istruire mod_cache per saltare il caching di richieste che iniziano con /admin-stacippa. Forse dovrete anche evitare che vengano messi in cache le richieste che hanno header quali Cookie e Set-Cookie, etc.
Problemi noti
Se dopo l’abilitazione di mod_cache emergono subito artefatti allucinanti, ad esempio se il visitatore vede la stessa pagina per tutti gli URL, allora vi risparmio le bestemmie: è colpa vostra e di mod_rewrite.
WordPress, infatti, usa mod_rewrite. Lo capite subito se avete URL fighetti tipo /2019-09-05/bao invece che un meno SEO-sexy ?p=666.
Questo funziona perchè a monte avrete sicuramente una regola del genere di mod_rewrite:
RewriteRule . /index.php [L]
Questa regola pesca qualsiasi indirizzo e risponde con l’output dell’esecuziome di index.php. In pratica un solo eseguibile genera ogni pagina. Il che è sensato ma per mod_cache comporterà un bel casino dato che, per ragioni su cui non ci è dato polemizzare, mod_cache avviene dopo mod_rewrite; e dato che la cache è salvata ovviamente sulla base dell’URL, questo significa che state mettendo in cache una sola pagina per tutte le richieste, perchè /welcome/ diventa /index.php e /about diventa /index.php etc.
Prima di passare a Varnish (asd) potete sfruttare questo mio workaround partorito durante una generosa seduta al bagno pensando immensamente a quanto fosse stimolante il binomio di un URL rewriter + mod_cache. Fra l’altro posso asserire con una vaga certezza che questa soluzione sia una mia idea. Ho trovato solo un altro tizio sul web che fa così ma in una domanda sgrammaticata e con una risposta che manco spiega il funzionamento. asd).
Ecco la variante:
RewriteRule ^(.*)$ index.php/$1 [L]
Funziona, perché /welcome/ diventerà un innocuo /index.php/welcome.
Perchè la richiesta/index.php/welcome dovrebbe essere lecita se quel file non esiste? Ottima domanda! Qui ti volevo. Funziona, perchè nel tuo webserver avrai attiva di default una delle mie direttive di Apache preferite, una di quelle che non conosce nessuno, ma proprio nessuno, ma, ripeto, è attiva in tutti i webserver del pianeta. Di default. In tutti. asd.
Parliamo di AcceptPathInfo. Se conosci questa direttiva significa che sei l’anticristo in persona e puoi vantarti di visitare indirizzi senza senso ottenendo una risposta valida. Esempio:
https://www.facebook.com/index.php
https://www.facebook.com/index.php/melone-prezzemolato
Come vedete, è una direttiva talmente sfigata che manco Facebook sa di averla, altrimenti l’avrebbe disabilitata o avrebbe impostato un reindirizzamento o dichiarato un URL canonico, cosa che al momento non fa (quindi potremmo avvelenare i loro risultati di ricerca linkando termini a caso su URL esistenti con termini a caso dentro! che bello. asd).
Va beh, torniamo a noi.
Funziona, perchè utilizzare il nome di un eseguibile esistente come se fosse una directory, provoca comunque l’esecuzione di tale eseguibile. L’URL di eccedenza (e.g. “melone-prezzemolato“) viene passato sotto banco allo script all’interno della variabile d’ambiente PATH_INFO.
In sostanza: fate in modo che agli occhi di mod_cache siano sempre tutte richieste differenti. Al contrario, per l’applicativo il meccanismo di caching deve rimanere del tutto trasparente. Notare che se l’applicativo non fa uso del PATH_INFO non farete danni nell’usare il mio workaround (come per WordPress); invece chi lo usa (come Joomla!-merda) allora semplicemente questo problema non se lo porrà perchè ogni URL sarà già univoco (affinchè non sembri che stia promuovendo Joomla!-merda, vorrei ricordare che ha una terribile gestione dei permalink e quindi avrete ben altri problemi tipo contenuti centuplicati su indirizzi a caso. Se non si fosse capito, non usate Joomla!-merda. Che fra l’altro è l’unico CMS famoso NON pacchettizzato per le principali distribuzioni GNU/Linux, talmente fa schifo.)
Concludendo
Cloudflare è per pigri. Anche un po’ per rincoglioniti. Voglio dire, c’è una rispettabile fetta di utenze di Cloudflare e di altri firewall e CDN, diciamo forse l’1% dei loro utenti, che effettivamente potrebbe meritare i servizi di Cloudflare, o di altri, poichè lo userebbero col senno dell’impossibilità di farselo in proprio per mancanza di risorse. Per il resto, mi rendo conto che centralizzare il web verso un unico fornitore di servizi possa sembrare una genialata, soprattutto per i fan di Stalin.
Insomma, fatevi da soli un server di caching o fatevelo fare. Ma fatevi qualcosa in proprio. Se ce l’ho fatta io, ce la fa chiunque. Il web é nato decentralizzato per qualche ragione. No?
A disposizione per chi interessassero ulteriori dettagli, però, principalmente, per entrare nello spirito giusto, basta partire dalla guida definitiva per velocizzare WordPress.